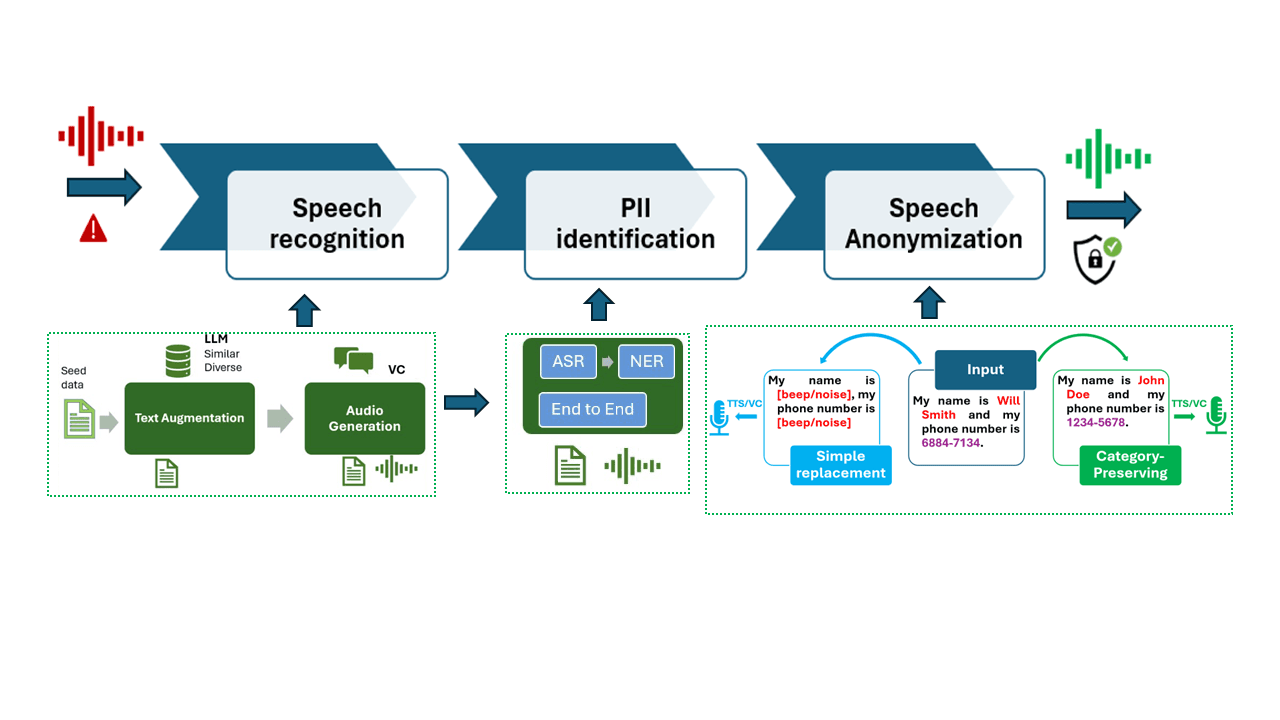
This project develops a speech de-identification system that anonymises spoken data by removing or modifying PII while preserving content and utility.
Project description:
Voice applications, from chatbots to assistants, transmit large amounts of personally identifiable information (PII), raising risks of misuse, privacy violations, and identity theft.
Solution and Notable Contribution:
The team explored three key aspects:
- LLM-based data augmentation to address the scarcity of PII-rich data
- PII identification modelling using both a pipeline approach (ASR + NER) and end-to-end methods (perform ASR and PII tagging simultaneously)
- Speech anonymisation techniques aimed at balancing data utility and anonymisation
Publications
- Yaodi Liu, Kun Zhang, Dianying Chen, Chenxi Cai, Xiaohe Wu, Rong Tong, “A discontinuous NER model based on token prediction and contrastive learning to enhance span“, The Journal of Super computing, Vol 81, no. 956, 2025
- Priyanshu Dhingra, Satyam Agrawal, Chandra Sekar Veerappan, Eng Siong Chng, Rong Tong, “Leveraging Large Language Models for Speech De-Identification “, , International Journal of Asian Language Processing, 2025
- CS Veerappan, P Dhingra, Zhengkui Wang, Rong Tong, SpeeDF-A Speech De-identification Framework, IEEE TENCON 2024
- Priyanshu Dhingra, Satyam Satyam, Chandra Sekar Veerappan, Chng Eng Siong, Rong Tong, Enhancing Speech De-identification with LLM-based Data augmentation, ICAICTA2024
![[FA] SIT One SITizen Alumni Initiative_Web banner_1244px x 688px.jpg](/sites/default/files/2024-12/%5BFA%5D%20%20SIT%20One%20SITizen%20Alumni%20Initiative_Web%20banner_1244px%20x%20688px.jpg)