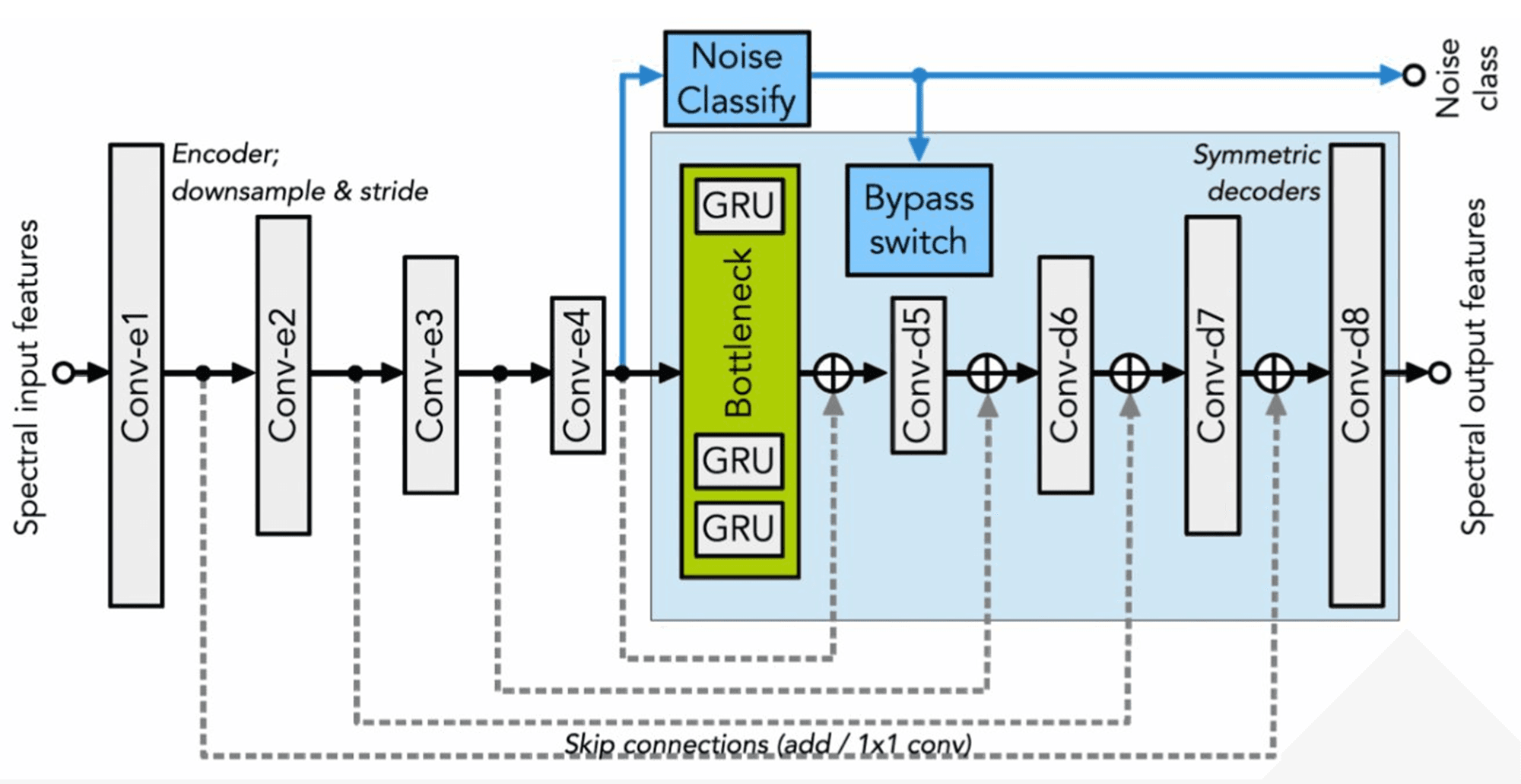
This project aims to develop a real-time speech denoising system that detects noise and senses speech to remove background noise and enhance clarity in industrial, commercial, or domestic environments.
Project Description:
The system should support any language and additive noise type, target <40 ms latency on embedded ARM CPUs, and achieve speech quality metrics of ITU-T P.808 MOS >3.5 and P.862 PESQ >3.5.
Solution and Notable Contribution:
All KPIs and performance targets met or exceeded. Handcrafted, standalone, highly tuned code (no APIs or libraries) achieves real-time latency of 30 ms on ST32MP1 ARM, with excellent speech quality (MOS 3.6).
Publications:
- Ian McLoughlin, Zhongqiang Ding, Bowen Zhang, Evelyn Kurniawati, A. B. Premkumar, Sasiraj Somarajan, Song Yan, “On the nature and potential of deep noise suppression embeddings”, Springer Journal of Circuits, Systems and Signal Processing (accepted March 2025, in press)
- Ian McLoughlin, Jeannie Lee, Indri Atmosukarto, Ding Zhongqiang, “DNN-based Speech Re-reverb for VR Rooms”, IEEE TENCON 2024, Singapore, Dec. 2024.
- Ian McLoughlin, Jeannie Lee, Indri Atmosukarto, “Single channel AI speech reverberation time modification for room dimension matching”, 23rd IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Seattle, USA, Oct. 2024.
Acknowledgements
A large multinational audio equipment manufacturer
![[FA] SIT One SITizen Alumni Initiative_Web banner_1244px x 688px.jpg](/sites/default/files/2024-12/%5BFA%5D%20%20SIT%20One%20SITizen%20Alumni%20Initiative_Web%20banner_1244px%20x%20688px.jpg)